gem5 cpu 模型
主要介绍 gem5 中的 cpu 模型。
BaseCPU
几乎处于 cpu 继承树的顶层,BaseCPU 是所有后续 cpu 的父类,它抽象出了一个非常简单的 cpu 模型,把后续所有 cpu 需要用到的公共功能封装到了这个 BaseCPU 中,这个 cpu 并不具备执行指令的能力。
BaseCPU 封装了如下的功能:
- 统计数据。抽象出一些公共的统计数据组,如
GlobalStats(ipc 就在这个统计数据组中计算)、FetchCPUStats(取值相关的统计信息)、ExecuteCPUStats和CommitCPUStats。 - 中端控制器相关的成员。为 BaseCPU 中运行的每个线程设置中断处理器,并且提供发送中断的接口。
- cpu 切换。BaseCPU 中包含了 cpu 切换、或者从其他 cpu 中恢复、清除 TLB 等函数。
- 获取端口。BaseCPU 中定义了从指令接收端口和数据接收端口获取端口的方法,子类中必须实现这些方法。也即子类中必须也得提供这几个端口。
- Thread 相关。
在 BaseCPU 中还声明了很多 probepoint,对外提供了监测点的实现方式,本以为这个监测点已经注册了回调函数到 manager 中,但是实际通过观察发现,这些监测点并没有注册相应的回调函数到 manager 中,因此对于 BaseCPU 中检测点的 notify 实际上是没有任何作用的。典型的如在 o3 的场景下,updateCycleCounters 就是一个没用的函数,看似在计算时间,实际上 notify 都没有其作用。对于各个统计数据的计算还是通过在程序中手动自增或者采集的方式计算的。
TimingSimpleCPU
主要解释 TimingSimpleCPU 的指令执行流程和 TimingSimpleCPU 中运行时钟周期的计算方法。
TimingSimpleCPU 的指令执行流程由下图给出: 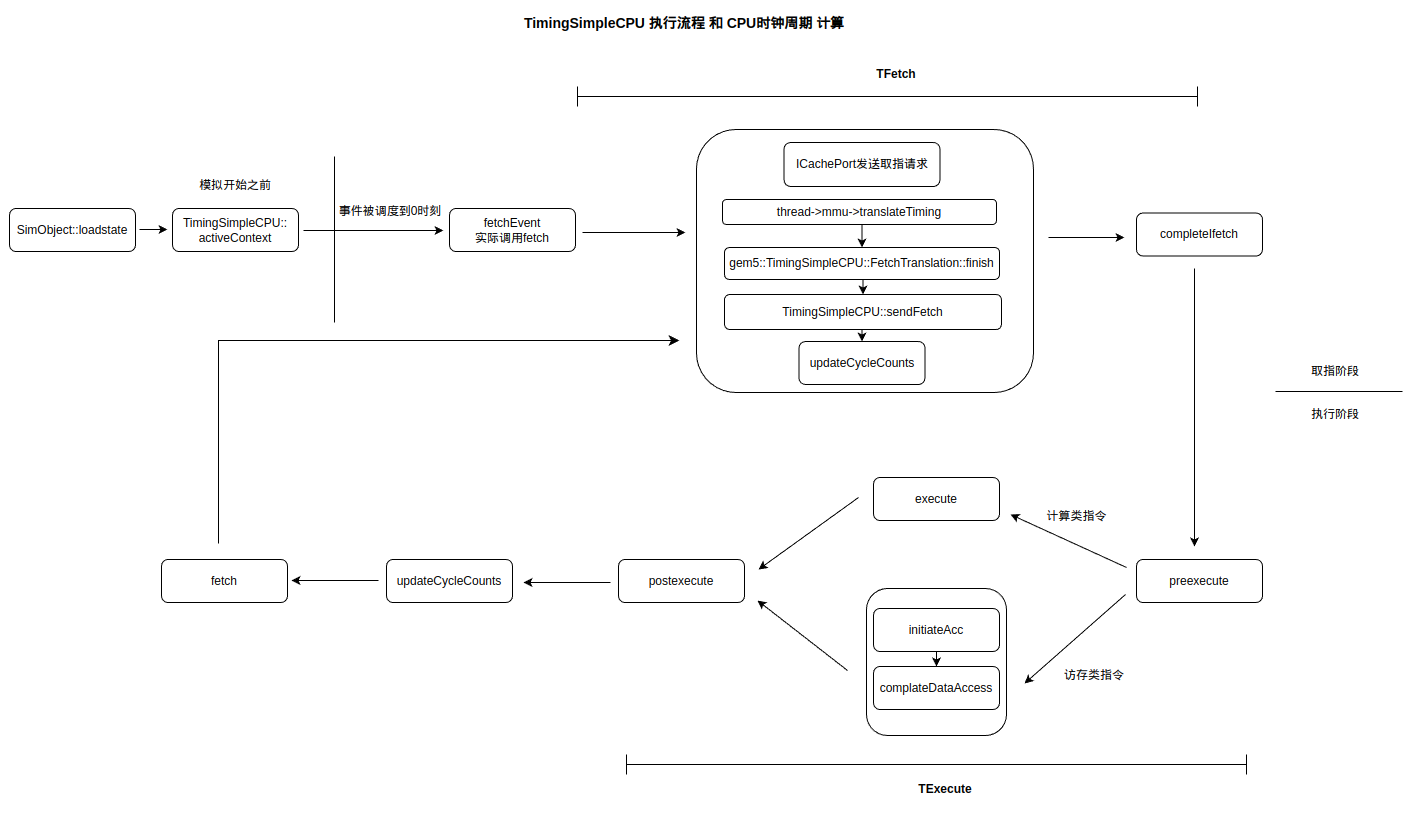
TimingSimpleCPU 的指令执行流程直接可以简单的分为取指和执行两个阶段,TimingSimpleCPU 周而复始的执行这两个阶段,顺序且无流水线。
下主要分析 TimingSimpleCPU 的时钟周期数的计算过程:设 TimingSimpleCPU 总共消耗的时钟周期为
其中
需要注意的是
AtomicSimpleCPU
AtomicSimpleCPU 一般是用来进行验证功能或者加速全系统仿真用的,所以考虑其 cpu 相关的统计数据是没有意义的,只需要对这个东西的大致执行流程有所了解就行了。AtomicSimpleCPU 支持指令发射宽度的设置,但是不认为这种宽度会加速模拟,我认为甚至可能减慢。
对于执行的流程直接参考官网的图片:
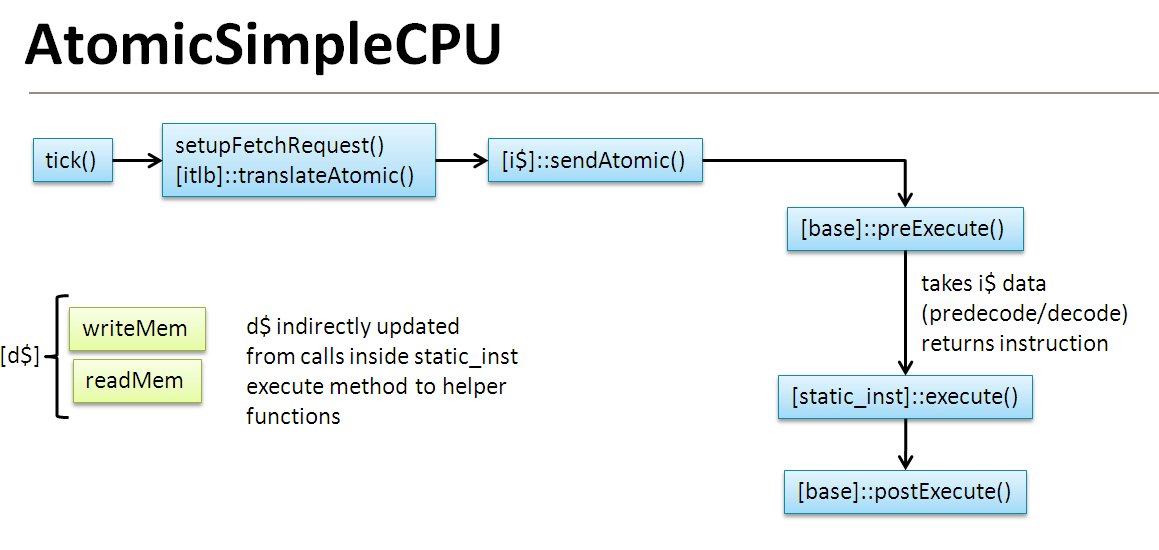
对这个模型没什么好说的。