单核内的内存序
“In forwarding, loads search older in-flight stores. In ordering, stores (in some processors loads too) search younger in-flight loads.”
Roth, Amir. "Store vulnerability window (SVW): Re-execution filtering for enhanced load optimization." 32nd International Symposium on Computer Architecture (ISCA'05). IEEE, 2005.
所谓前递,就是 load 对正在完成过程中(执行过程、提交过程、退役过程)但是尚未更新到存储层次的 store 的查询。所谓排序,就是 store 对正在执行的 load 的查找对比。我认为,更一般的,所谓排序,就是更老的存储指令对更新的存储指令的查找对比。
对于单核内的内存序,或者说是乱序访存单元的实现可能是多种多样的,并没有一种固定的说法。所有的实现,只要能保证机器乱序执行的正确,都是可行的,只是效率不一定达标。
乱序处理器中的单核内存序
SC 顺序一致性的,也就是说程序序等于机器序,简单的来讲,你在汇编程序中按顺序看到的存储指令就是按照看到的顺序在访问存储、更新存储层次。无论多核之间的一致性如何,单核之间的内存序都是顺序一致性的。单核中的内存序能不能不是顺序一致的?理论上来说也行,但是这就导致了编程的苦难,即使是单线程的程序,现在也需要在程序中使用同步指令,这是不符合编程直觉的,这种编程模型是不能被人类接收的,因此现在在单核内都是顺序一致的。
对于乱序处理器来说,在乱序发射乱序执行的同时还要保证顺序一致性是非常重要的,这也就导致了乱序超标量处理器中内存访问单元与内存队列的设置是复杂的,且是有多种设计方案的。
乱序处理器中的 load 与 store
超标量处理器的视图
首先展现乱序处理器的一个视图:
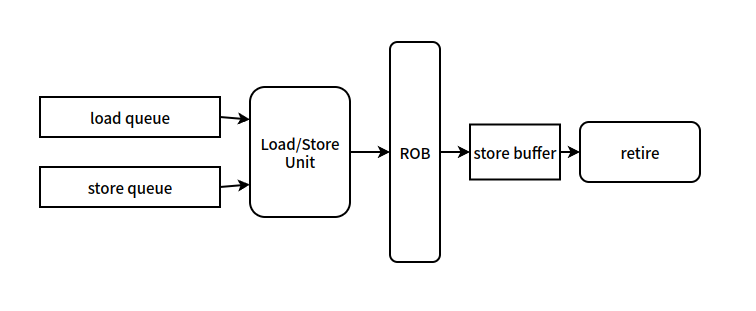
超标量处理器的视图如图所示,load queue 和 store queue 即是 load 和 store 中的保留站,这些保留站的设计是多样的,里面可能保存了各种状态和信息。Load/Store Unit 即 load/store 的执行单元。ROB即重排序缓冲。store 在提交之后会进入 store buffer,后续写回到存储层次的时间是不定的,当其写回存储层次的时间是不定的,当其写回存储层次之后会进行 retire 退役,并从 store buffer 中清除相关的 store 指令。
这是典型的超标量乱序的处理器的视图。但是与内存序或者 load/store queue 设计的相关论文中视图可能不是这个样的,具体情况得看论文中怎么描述。
超标量处理器中的 load/store
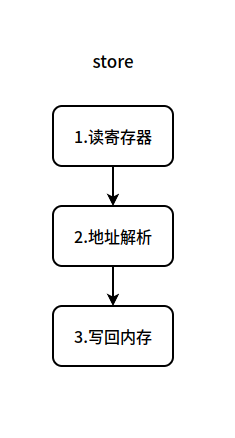
超标量处理器中 store 的生命周期如图:
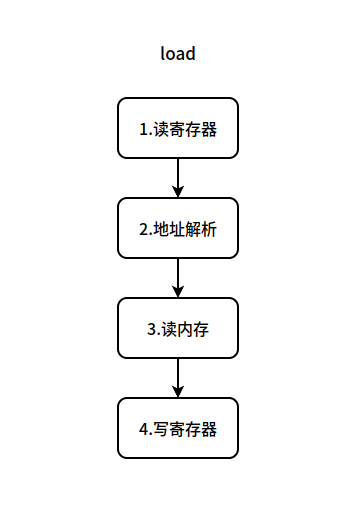
超标量处理器中 load 的生命周期如图:
现在要决定各个过程如何分布在超标处理器的各个阶段中。
对于超标量处理器而言,在 commit 阶段之前,在它的眼中只有机器状态,也就是所谓的寄存器的状态,它只进行能够改变寄存器状态的操作,以此来维护处理器的高效,对于不涉及寄存器的操作,在 commit 阶段之前都尽量不执行。对于存储层次相关的操作,根据其对体系结构寄存器状态的影响的不同,超标量处理器对他们有不同的做法。
对于 store 指令的生命,三个过程分别如下:
- 读寄存器:读取相关的寄存器,其中包括写入内存的寄存器还可能包括用于复杂寻址模式的寄存器。
- 地址解析:根据指令的寻址模式,计算出即将写入的地址。
- 写回内存:将相关寄存器中的值写回内存。
对于这三个过程,第 3 个过程并不涉及对于寄存器的更改,因此第三部分可以在指令提交后再去慢慢写回内存。因此对于上面的处理器视图:
- 发射:在 1 中相关的寄存器值能够读取的时候。
- 执行:计算即将写回的地址,将 (addr, write_value) 写到 store buffer 中。
- 提交:提交指令。
- 退役:在退役阶段完成内存的写回。
在上面这个处理器的视图下,提交阶段之前并没有完成内存的写回,而是在提交之后才进行写回操作。
对于 load 指令的生命,四个过程如下:
- 发射:在 1 中相关的寄存器值能够读取的时候,在 4 中寄存器的值能够写回的时候。
- 执行:计算即将读取的地址,访问即将读取的地址,数据来源可能是 cache 也可能是 store buffer 中数值的前递,将读取的数值写回寄存器。
- 提交:提交指令。
在上面的处理器视图下,提交阶段之前,load 指令所有的工作都完成了。
在看 store,它是寄存器的消费者,内存值的生产者。load,它是寄存器值的生产者和消费者,是内存值得消费者。
乱序处理器中单核 SC 的实现
现在来讲对于乱序超标量的处理器,单核中的 SC 应该如何实现。SC 实现的难点在于 load 和 store 能够发射的时机,由于超标量处理器的乱序执行引擎根本不关注内存的值是否更新完成,因此只要 load 和 store 满足发射条件就能够发射执行了,考虑有
最简单的实现
最简单的实现无非就是将乱序退化成顺序来保证 SC。这种实现方案的架构图如下:
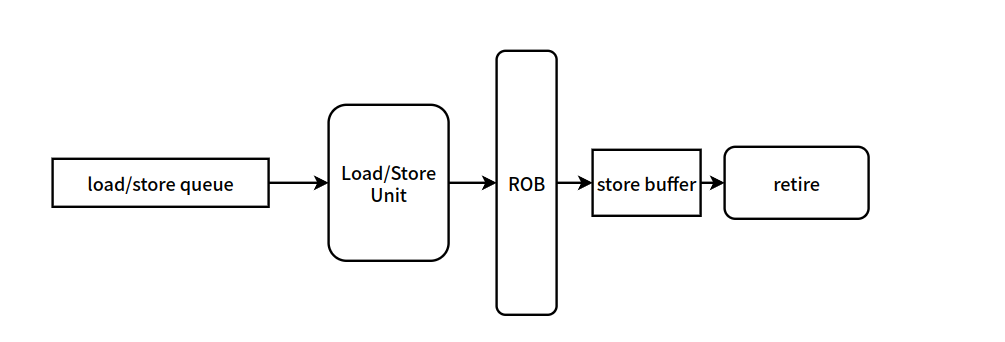
这种方案直接将 load queue 和 store queue 合并到一条队列中,并规定队列中每一个 load / store 的发射条件,只有在他们前面的 load / store 进入到了 ROB 之后,他们才能发射执行。这种规定简单的来讲就是在前面的操作还没有完成的时候,后面的操作是不允许提前进行的,这显然维护了 SC。这种实现方式是最简单的,但是效率是最低的,他完全将乱序发射乱序执行降级成了顺序发射顺序执行,效率显然是降低的。
可能性的优化空间在于对于 load/store queue 中的内存操作,他们访问的并非都是同一个内存地址,他们之间不一定会产生写后读的依赖关系,在上面的实现中,即使 load/store queue 中的操作不存在依赖关系,后面具备发射条件的表项也不能前于前面的表项进行,这是效率低下的点,也是优化的一种可能。
最直接的实现-load前提
需要记住,无论如何去做实现,永远都要保证 SC,即不管你内部发生了什么,在外部看来或者说是从编程模型的角度上看都是要满足 SC 的。某些情况下,可能内部不按照 SC 的方式去执行,但是得到的结果满足 SC 的,同不违反 SC 的时候没有区别,这时候这种内部执行的方式是允许的,毕竟内存序的定义只规定了最终状态和程序序的关系,但是并没有指定你一定要按照严格按照什么顺序去执行程序。
最简单的例子就是上面提到的对于 load/store queue 中的内存操作,他们访问的并非都是同一个内存地址的情况,也就是说有
这个问题产生的原因是 load 在满足发射的时候,store 尚未解析出其地址,导致其违反了一致性。因此在 store 进入到保留站之后,需要对内存队列中尚在执行的比这个 store 年纪更轻的 load 进行检测,如果发现了
:::detail 需不需要担心 store 之前的 load? 这里会有一个问题是需不需要担心 store 之前的 load,担心可能存在这种情况 store 先于排在它 load 发射,但是这个 load 的地址是 store 要修改的地址。如果 store 提前修改了这个地址上的值,load 就会读到一个新的值。这是不需要担心的,因为我们的优化方案里只允许 load 提前,而没有允许 store 的提前。根据 SC,
简单的来讲,当前这种简单实现的方案相对于前面提到的顺序实现,其本质只是允许了 load 的前提,其他的某些部分还是要保持顺序的,像上面方框中提到的,比如程序中晚于 load 出现的 store,就不能提前。
:::detail 内存依赖预测 所谓的某些内存依赖的预测,就是在判断这种方案中哪些 load 能提前哪些 load 不能提前,尽量提高 load 提前的精准度,防止频繁的 load 提前导致的重新执行。内存依赖预测也不仅仅于此,但是需要关注的是其内部设计的乱序执行更加复杂,恢复措施也更加复杂,但是无论怎样他们都是会用一套方案保证 SC 的。 :::
其他实现方案
先前的方案相对于顺序执行的实现方案来说只是宽松了
只是在执行时候松散掉的规则越多,乱序执行的程度就越高,虽然在速度上达到了极致,但是错误带来的开销可能抹掉速度上的提升。乱序的程度越高,带来的检测措施也越复杂,比如宽松了
需要注意的点
- 在单核内,乱序执行的时候可以不满足
这条规则而不需要任何验证措施。考虑有内存序列 ,假设 、 是任何内存序列,在这种情况下交换 、 的发射执行顺序并不会对最后的结果产生什么影响,在外部看来整个处理器仍然是 SC 的。交换 、 的位置除了改变 这条规则之外,并没有对其他执行规则进行违反。同时在单核内 、 都是内存的消费者,不管他们访问的是不是同一个内存位置,交换都不会产生任何的影响。注意这里强调的是仅仅交换两个 load 的位置,而没有改变其他执行顺序。